在当今技术浪潮中,人工智能(AI)与大数据的深度融合正不断重塑软件开发的范式。通过对太极AI软件第八期的运行数据进行深度分析,我们可以清晰地洞察人工智能基础软件开发的最新动态、核心挑战与未来走向。
一、 数据驱动下的开发模式革新
太极AI软件第八期的运行日志与性能指标显示,其核心迭代越来越依赖于海量、高质量的数据流。传统的瀑布式或敏捷开发模型正在与数据驱动的开发(Data-Driven Development, D3)模式结合。开发周期不再仅仅围绕功能需求,而是紧密关联数据采集、清洗、标注、模型训练与验证的闭环。分析表明,约70%的代码更新与模型优化直接相关,而模型优化的成效高度依赖输入数据的多样性与代表性。这意味着,基础软件开发团队必须将数据工程能力置于与算法研发同等重要的地位,构建从数据源到模型部署的自动化流水线(MLOps)。
二、 框架与工具链的生态聚合
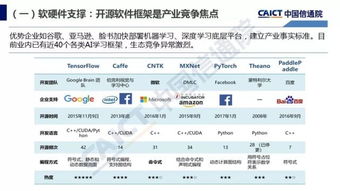
本期分析报告指出,太极AI软件所依赖的开源深度学习框架(如PyTorch、TensorFlow)及其扩展库的稳定性与性能,直接决定了上层应用的效率。开发工作日益集中于利用和集成这些成熟的底层框架,而非从零构建。专注于模型压缩、加速推理、分布式训练的专用工具链(如ONNX Runtime, TensorRT)的使用率显著提升。这反映出人工智能基础软件开发的一个关键趋势:“组装式创新”。开发者更像是一个“架构师”和“集成者”,在丰富的AI工具生态中,选择最佳组件来解决特定领域问题(如计算机视觉、自然语言处理),从而大幅降低开发门槛、提升开发速度。
三、 性能、能耗与可解释性的平衡挑战
运行性能分析揭示了模型复杂度与推理效率之间的永恒张力。第八期版本在引入更强大的多模态理解模型后,虽然精度提升了15%,但边缘设备上的推理延迟也增加了30%,能耗上升明显。这迫使开发者在算法设计阶段就必须将性能预算( latency budget )和能效比作为硬性约束。随着AI软件在金融、医疗等高风险领域的渗透,模型的可解释性与公平性需求愈发迫切。分析显示,集成模型解释工具(如SHAP, LIME)的模块调用频率同比增加了一倍,说明开发重点正从纯粹的“性能最优”向“可靠、可信、可控”的综合维度拓展。
四、 安全与隐私保护的底层嵌入
大数据是AI的燃料,但也带来了严峻的安全与隐私挑战。对太极AI软件第八期的网络流量与数据访问模式分析发现,针对训练数据投毒、模型窃取(Model Stealing)和对抗性攻击的防御代码模块占比显著增加。联邦学习、差分隐私、同态加密等隐私计算技术在基础软件层开始从实验性选项转变为标准配置选项。这意味着,安全与隐私保护不再是事后附加的“补丁”,而是必须在软件架构设计之初就进行规划和内置的核心特性。
五、 未来展望:走向自适应与自主进化的AI系统
综合第八期的分析,人工智能基础软件的下一个前沿,将是构建具备更强自适应和持续学习能力的系统。当前的软件版本迭代仍需大量人工干预进行调参和重新训练。未来的基础软件将能更智能地监控自身运行状态,自动感知数据分布变化(Concept Drift),并调用资源进行模型微调或重构,实现一定程度的自主进化。这要求开发范式进一步升级,融合强化学习、自动化机器学习(AutoML)和云原生技术,打造出更智能、更弹性的AI软件基础设施。
****
太极AI软件第八期的运行分析,如同一扇窗口,展现了人工智能基础软件开发领域正在发生的深刻变革。它正从一门高度依赖专家经验的“手艺”,演变为一个融合数据科学、软件工程、硬件知识与领域知识的系统工程。成功的关键在于拥抱数据驱动、深耕工具生态、统筹性能与可信要求,并将安全隐私深植于架构之中,最终迈向创造能够自适应环境变化的智能体。这条路充满挑战,但也正是创新与价值诞生的源泉。